Synchronized原理剖析
synchronized关键字原理在我个人看来应该是java中最难的几个问题之一了。其用法不难,但里面涉及的知识点很多。它作为关键字提供了并发环境中多线程的同步机制,但就是因此,我们无法直观的看到它的源码,从而很难探究它的底层原理。
synchronized用法
synchronized可以修饰方法或者代码块:
- 方法:
- 静态方法
- 实例方法
- 代码块:
- 实例对象
- class对象
我们不会看它如何使用,而是主要探究其原理,同样的,本文适合对于synchronized关键字有一定使用经验的人。接下来通过反编译来看看它的究竟。
synchronized作用于代码块
1 | public class Result { |
通过反编译可得:
1 | public static void main(java.lang.String[]) throws java.lang.InterruptedException; |
注意第4行的monitorenter和14行的monitorexit,也就是在synchronized作用于代码块时,JVM通过这两个指令进行了同步,那么它们如何保证同步的呢?我们后面会分析。
synchronized作用于方法
1 | public class Result { |
反编译可得:
1 | public synchronized void test(); |
注意到字节码的flags中多了一个ACC_SYNCHRONIZED,也就是synchronized作用于方法时,JVM在方法访问标识符flags中加入ACC_SYNCHRONIZED来实现同步。
monitorenter、monitorexit和ACC_SYNCHRONIZED
我们会根据oracle提供的jvm规范文档来介绍这三个指令。
monitorenter
Each object is associated with a monitor. A monitor is locked if and only if it has an owner. The thread that executes monitorenter attempts to gain ownership of the monitor associated with objectref, as follows:
If the entry count of the monitor associated with objectref is zero, the thread enters the monitor and sets its entry count to one. The thread is then the owner of the monitor.
If the thread already owns the monitor associated with objectref, it reenters the monitor, incrementing its entry count.
If another thread already owns the monitor associated with objectref, the thread blocks until the monitor’s entry count is zero, then tries again to gain ownership.
翻译过来就是:
每个对象都与一个monitor相关联。当且仅当拥有所有者时(被拥有),monitor才会被锁定。执行到monitorenter指令的线程,会尝试去获得对应的monitor,如下:
每个对象维护着一个记录着被锁次数的计数器, 对象未被锁定时,该计数器为0。线程进入monitor(执行monitorenter指令)时,会把计数器设置为1.
当同一个线程再次获得该对象的锁的时候,计数器再次自增.
当其他线程想获得该monitor的时候,就会阻塞,直到计数器为0才能成功。
monitorexit
The thread that executes monitorexit must be the owner of the monitor associated with the instance referenced by objectref.
The thread decrements the entry count of the monitor associated with objectref. If as a result the value of the entry count is zero, the thread exits the monitor and is no longer its owner. Other threads that are blocking to enter the monitor are allowed to attempt to do so.
翻译过来就是:
monitor的拥有者线程才能执行monitorexit指令。
线程执行monitorexit指令,就会让monitor的计数器减一。如果计数器为0,表明该线程不再拥有monitor。其他线程就允许尝试去获得该monitor了。
ACC_SYNCHRONIZED
Method-level synchronization is performed implicitly, as part of method invocation and return. A synchronized method is distinguished in the run-time constant pool’s method_info structure by the ACC_SYNCHRONIZED flag, which is checked by the method invocation instructions. When invoking a method for which ACC_SYNCHRONIZED is set, the executing thread enters a monitor, invokes the method itself, and exits the monitor whether the method invocation completes normally or abruptly. During the time the executing thread owns the monitor, no other thread may enter it. If an exception is thrown during invocation of the synchronized method and the synchronized method does not handle the exception, the monitor for the method is automatically exited before the exception is rethrown out of the synchronized method.
翻译过来就是:
方法级别的同步是隐式的,作为方法调用的一部分。同步方法的常量池中会有一个ACC_SYNCHRONIZED标志。
当调用一个设置了ACC_SYNCHRONIZED标志的方法,执行线程需要先获得monitor锁,然后开始执行方法,方法执行之后再释放monitor锁,当方法不管是正常return还是抛出异常都会释放对应的monitor锁。
在这期间,如果其他线程来请求执行方法,会因为无法获得监视器锁而被阻断住。
如果在方法执行过程中,发生了异常,并且方法内部并没有处理该异常,那么在异常被抛到方法外面之前监视器锁会被自动释放。
那么我们多次提到的monitor究竟是个什么东西呢?
monitor监视器
操作系统中的管程
我们都知道管程在操作系统中提供了一种机制,它提供线程间的互斥访问。
实际上,操作系统中的管程是概念原理,或者说是一种规范,而ObjectMonitor是它在JVM(HotSpot)中的具体实现。
ObjectMonitor
数据结构(定义)
在HotSpot中,ObjectMonitor的主要数据结构如下:
1 | ObjectMonitor() { |
重点字段已经使用“*”标记出来了。
工作原理
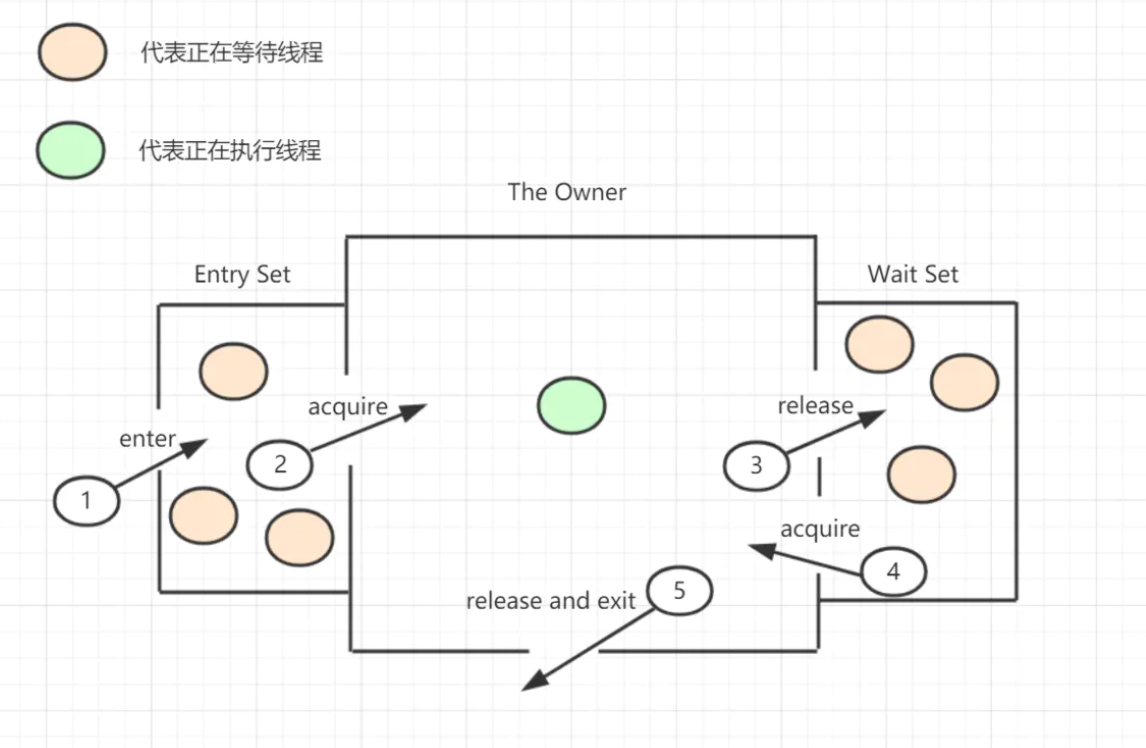
- 想要获取monitor的线程,首先会进入_EntryList队列;
- 当某个线程获取到对象的monitor后,进入_Owner区域,设置为当前线程,同时计数器_count加1;
- 如果线程调用了wait()方法,则会进入_WaitSet队列。它会释放monitor锁,即将_owner赋值为null,_count自减1,进入_WaitSet队列阻塞等待;
- 如果其他线程调用 notify() / notifyAll(),会唤醒_WaitSet中的某个线程,该线程再次尝试获取monitor锁,成功即进入_Owner区域;
- 同步方法执行完毕了,线程退出临界区,会将monitor的owner设为null,并释放监视锁。
以代码为例:
1 | synchronized(this) { //进入_EntryList队列 |
对象如何与monitor关联
对象是如何与monitor关联起来的呢?
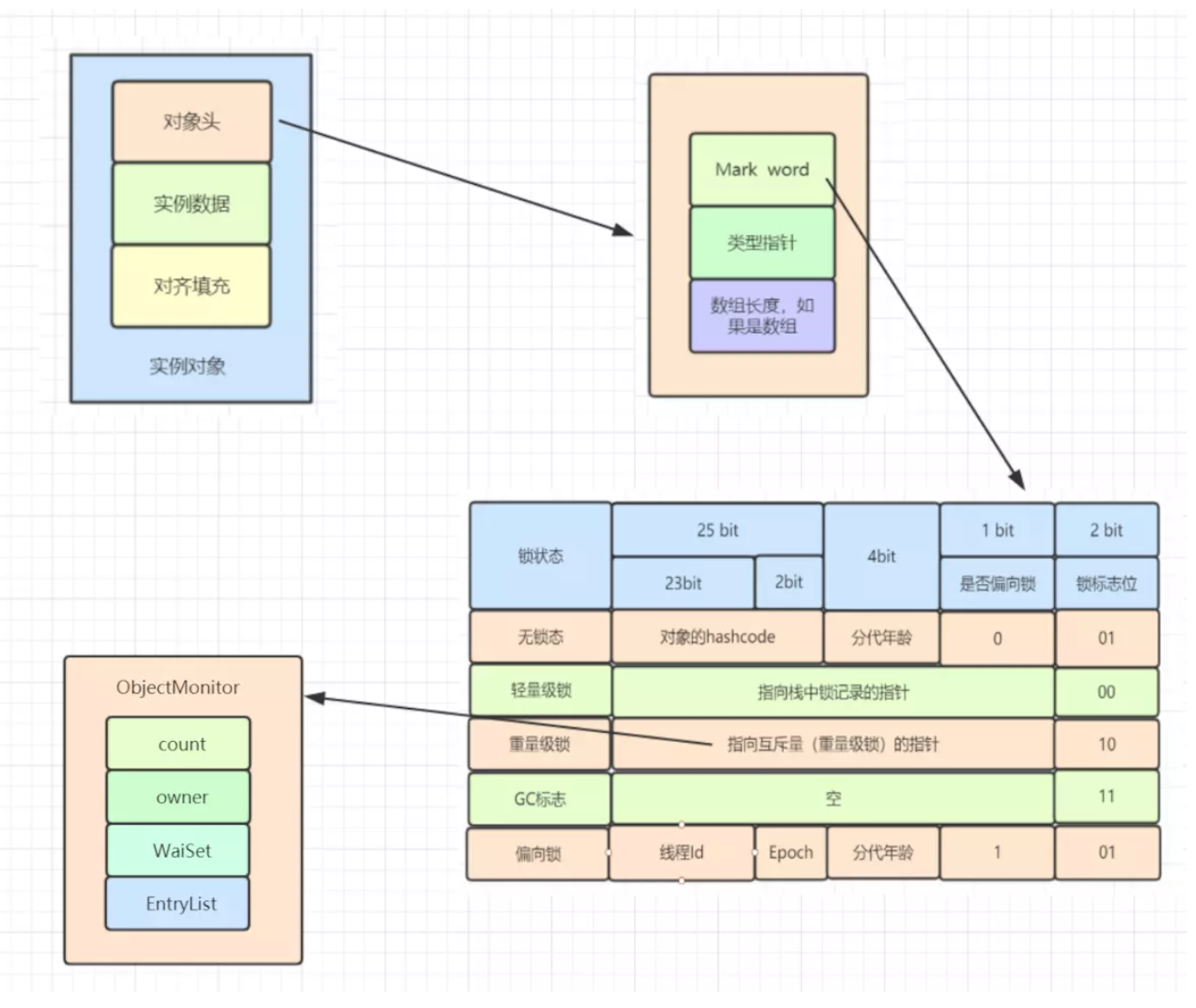
由此可见,实例对象中有一个对象头,在对象头的Mark word中,如果这个对象被上了重量级锁,Mark word中会有一个指向互斥量(重量级锁)的指针,指向ObjectMonitor对象,从而实现了对象与monitor的关联。
接下来我们就一层一层的看下去,这中间令人一头雾水的各个名词都是什么意思?以及什么原理?
Java对象内存布局
由上图可见,在JVM中,对象在堆中的布局可以分为三块:对象头、实例数据和对齐填充。
那么我们如何证明这一点呢?口说无凭啊。我们可以通过一个依赖包来打印对象的内存布局:
1 | <dependency> |
然后简单创建个对象就可以打印出来:
1 | // 定义一个类 |
输出结果:
1 | com.leetcode.L object internals: |
其中的object header就是我们说的“对象头”,中间的L.flag实际上就是我们上面定义的L类实例的对象l的“实例数据”,自此总共有13 bytes。
但64位的JVM要求对象大小必须是8个bytes的倍数,也就是即使只有一个boolean是1 byte,也要加上7 bytes的字节填充。上面的输出中“loss due to the next object alignment”我们可以看到在基于原来的13 bytes基础上,又加上了3 bytes的“字节填充”,刚好可以解释我们上面画的图是正确的。
对象头
这里我们只看上面对象头部分的数据:
1 | OFFSET SIZE TYPE DESCRIPTION VALUE |
在我的64位机器上拿到的对象头是12 bytes,也就是96 bits(有些同学会测出来128 bits,这是因为有些机器开启了指针压缩造成的,这里不做详述)。
JVM规范:对象头是每个gc管理的堆对象的公共结构,包括堆对象的:
- 布局;
- 类型(存放指向元空间类模板的指针);
- gc状态(4位bit);
- 同步状态(后面会说);
- 哈希码(此处注意,hashcode并不存在*);
的基本信息。所有的java对象和jvm内部对象都有一个通用的对象头格式。
根据JVM规范,对象头 = mark word(8byte) + klass pointer(4byte) = 12 bytes。其中klass pointer就是元空间内类的模板信息(指针)。如果是数组,还有4个byte记录长度 + 长度的动态byte数。
那么我们现在知道了,后面的4个bytes是类模板的指针,那前8个bytes的Mark word又是什么?每一位都表示什么呢?
Mark word
Mark word中存放了堆对象的gc状态、同步状态、哈希码等信息,但其实这里面也有坑(hash码真的存了吗)。
我们先来看一下不同状态锁的时候,Mark word的表现:
| Object Header(96 bits) | ||
|---|---|---|
| Mark word(64 bits) | Klass word(32 bits) | |
| unused: 25 | hashcode: 31 |unused: 1 | age: 4| blased_lock: 1| lock: 2 | pointer to metadata object | 无锁 |
| thread: 54 | epoch: 2| unused: 1| age: 4|blased_lock: 1| lock: 2 | pointer to metadata object | 偏向锁 |
| —————– ptr_to_lock_record: 62 —————–| lock: 2 | pointer to metadata object | 轻量锁 |
| —————– ptr_to_heavyweight_monitor: 62 —————–| lock: 2 | pointer to metadata object | 重量锁 |
| —————————————————————————————————————————- | lock: 2 | pointer to metadata object | gc |
注意这里的ptr_to_heavyweight_monitor,后面我们会对它进行分析。
1、同步状态:
需要blased_lock(偏向锁标识)和lock(锁状态标识)共同表示前两种状态:
- blased_lock:0,lock:01:表示无锁;
- blased_lock:1,lock:01:表示偏向锁;
- lock:00:表示轻量锁;
- lock:10:表示重量锁;
- lock:11:表示gc标志。
这是因为lock的2个bits只能表示4种状态,故而引入了1个bit标识偏向锁,而后的三种状态都没有blased_lock啥事儿了,用lock就够了。
2、gc状态:age字段表示gc状态,age只有4个bits,能表示的最大数字是15,这也就解释了为什么对象在young区的from和to交换15次就放到old区。
3、哈希码
这里大家可能跟我有一样的困惑,前8个bytes都是0,只有一个bit是1,哪里存的hash码?如此说来,那hash码真的存在于对象头吗?
我们在上面分析对象头时,用*标记了说明hash码其实是并不存在的,hashcode存的是地址,这个地址是需要计算出来的并不是绝对的内存地址。事实上object.hashcode()方法也是native方法,需要有计算过程,地址这个东西毕竟只有cpp才能知道。
那我怎么在对象头中显示hash码呢?很简单,上面手动调用hashcode()方法,hash码就会被存到对象头里面了。
1 | System.out.println(l.hashCode()); |
输出为(对象头只贴value部分):
1 | 1625635731 // hashcode |
这样,hash码就出来了,这里细心的同学可能又要问了,那我算出来的01 93 3b e5 60得到的和调用hashcode()方法不一样啊,是不是搞错了?
这里还涉及到一个小知识点,就是计算机bit的大小端存储问题,至少在我的机器上是采用大端存储的,还记得刚刚无锁时对象头的bit分布吗?unused: 1|age: 4|blased_lock: 1|lock: 2这里一共8个bit,刚好是前面第一个0x01(最后一001表示无锁状态)。接下来按照倒序来讲就应该是hashcode了,并且这几个16进制数内部也是倒序的,所以应该是60 e5 3b 93的10进制刚好是1625635731,这和上面手动调用hashcode()方法得到的结果是一致的。
再强调一遍,正常来讲对象头预留了hashcode位,但初始是不存储的,需要计算。
Mark word中的重量锁
还记得上面我们留的坑吗?ptr_to_heavyweight_monitor在重量锁的情形下,Mark word中的后62个bits(大端存储机器)指向的就是堆中ObjectMonitor对象,仅此一句话而已。
其实到这里,synchronized原理我们已经剖析完了。难吗?不了解对象的内存布局可能一辈子都不知道咋实现的,因为也没有源码。但是简单吗?清晰地分析下来发现,synchronized就是通过两个指令和一个flag来操控ObjectMonitor对象,而这个monitor对象通过对象头中存储的地址来访问。
锁优化
后面的jdk版本中(jdk 1.6之后),使用synchronized不会直接调用monitor的enter()和exit()方法了,直接调用被称作重量级锁,所以进行了一些锁优化,包括适应性自旋、锁消除、锁粗化、锁膨胀等一系列优化策略。
自旋锁
当临界区很小的情况下,锁占用的时间很短,那么频繁的阻塞和唤醒对于CPU来说开销太大了,所以采用自旋的方式减少CPU从用户态转为核心态切换的时间。
锁消除
有些程序员写代码时,上来就对一个实例进行sync,也不管究竟有没有竞争。JVM会在运行时检测,对于不存在共享数据竞争的锁进行消除。
锁粗化
锁粗化是指对于一系列要加锁的操作,JVM会将它们连在一起,扩展成一个范围更大的锁,举个例子:
1 | static L l = new L(); |
如果每次循环进去都加锁解锁简直是灾难,JVM会优化成下面这个样子:
1 | static L l = new L(); |
锁膨胀
锁膨胀指的是jdk 1.6之后针对于synchronized关键字做的优化,根据被锁资源的竞争程度,进行无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁的升级过程,而不是上来就上个重量级锁。
- 偏向锁:只有一个线程进入临界区;
- 轻量级锁:多个线程未竞争或者竞争不激烈,同步块执行速度非常快;
- 重量级锁:多线程竞争,高吞吐量,同步块执行时间较长。