python内存管理
本文主要为了解释清楚python的内存管理机制,首先介绍了一下python关于内存使用的一些基本概念,然后介绍了引用计数和垃圾回收gc模块,并且解释了分代回收和“标记-清除”法,然后分析了一下各种操作会导致python变量和对象的变化,最后做了一下小结。
Python变量、对象、引用、存储
python语言是一种解释性的编程语言,它不同于一些传统的编译语言,不是先编译成汇编再编程机器码,而是在运行的过程中,逐句将指令解释成机器码,所以造就了python语言一些特别的地方。例如a = 1,其中a是变量,1是对象。这里所谓的变量,它的意义类似一个指针,它本身是没有类型的,只有它指向的那个对象是什么类型,它才是什么类型,一旦把它指到别的地方,它的类型就变了,现在指向的是1,它的类型可以认为是int,假如接下来执行a = 2.5,那么变量的类型就变了。甚至当先给a=1,a = a + 1时,a的地址也会改变。而这里的1,2.5或者一个list一个dict就是一个被实例化的对象,对象拥有真正的资源与取值,当一个变量指向某个对象,被称为这个对象的产生了一个引用,一个对象可以有多个变量指向它,有多个引用。而一个变量可以随时指向另外的对象。同时一个变量可以指向另外一个变量,那么它们指向的那个对象的引用就增加了一个。
Python有个特别的机制,它会在解释器启动的时候事先分配好一些缓冲区,这些缓冲区部分是固定好取值,例如整数[-5,256]的内存地址是固定的(这里的固定指这一次程序启动之后,这些数字在这个程序中的内存地址就不变了,但是启动新的python程序,两次的内存地址不一样)。有的缓冲区就可以重复利用。这样的机制就使得不需要python频繁的调用内存malloc和free。下面的id是取内存地址,hex是转成16进制表示。
1 | #第一次启动解释器 |
针对整数对象,它的内存区域似乎是一个单独的区域,跟string、dict等的内存空间都不一样,从实验结果来看,它的地址大小只有’0xe5be00’,其他的是’0x7fe7e03c7698’。而存储整数对象的这块区域,有一块内存区域是事先分配好的,即[-5,256]范围内的整数。这块称为小整数缓冲池,静态分配,对某个变量赋值就是直接从里面取就行了,在python初始化时被创建。而另外的整数缓冲池称为大整数缓冲池,这块内存也是已经分配好了,只是要用的时候再赋值。可以从下面的例子中看到,针对257这个数字,虽然给a和b赋了相同的值,但是解释器实际上是先分配了不同的地址,再把这个地址给两个变量。
1 | a = 1 |
针对string类型,它也有自己的缓冲区,也是分为固定缓冲区和可重复缓冲区,固定的是256个ASCII码字符。还发现一个有意思的现象,string中只要不出现除了字母和数字其他字符,那么对a和b赋同样的值,它们的内存地址都相同。但是如果string对象中有其他字符,那么对两个变量赋相同的string值,它们的内存地址还是不一样的。
1 | b = 'aaaaaaaaaaaaaaaaaaaa' |
而另外的dict和list的缓冲区也是事先分配好,大小为80个对象。
因此变量的存储有三个区域,事先分配的静态内存、事先分配的可重复利用内存以及需要通过malloc和free来控制的自由内存。
Python内存管理机制和操作对变量的影响
内存管理机制
python的内存在底层也是由malloc和free的方式来分配和释放,只是它代替程序员决定什么时候分配什么时候释放,同时也提供接口让用户手动释放,因此它有自己的一套内存管理体系,主要通过两种机制来实现,一个是引用计数,一个是垃圾回收。前者负责确定当前变量是否需要释放,后者解决前者解决不了的循环引用问题以及提供手动释放的接口。
引用计数
引用计数(reference counting),针对可以重复利用的内存缓冲区和内存,python使用了一种引用计数的方式来控制和判断某快内存是否已经没有再被使用。即每个对象都有一个计数器count,记住了有多少个变量指向这个对象,当这个对象的引用计数器为0时,假如这个对象在缓冲区内,那么它地址空间不会被释放,而是等待下一次被使用,而非缓冲区的该释放就释放。
这里通过sys包中的getrefcount()来获取当前对象有多少个引用。这里返回的引用个数分别是2和3,比预计的1和2多了一个,这是因为传递参数给getrefcount的时候产生了一个临时引用。
1 | from sys import getrefcount |
当一个变量通过另外一个变量赋值,那么它们的对象引用计数就增加1,当其中一个变量指向另外的地方,之前的对象计数就减少1。
1 | a = [] |
垃圾回收
垃圾回收(Garbage Collection),python提供了del方法来删除某个变量,它的作用是让某个对象引用数减少1。当某个对象引用数变为0时并不是直接将它从内存空间中清除掉,而是采用垃圾回收机制gc模块,当这些引用数为0的变量规模达到一定规模,就自动启动垃圾回收,将那些引用数为0的对象所占的内存空间释放。这里gc模块采用了分代回收方法,将对象根据存活的时间分为三“代”,所有新建的对象都是0代,当0代对象经过一次自动垃圾回收,没有被释放的对象会被归入1代,同理1代归入2代。每次当0代对象中引用数为0的对象超过700个时,启动一次0代对象扫描垃圾回收,经过10次的0代回收,就进行一次0代和1代回收,1代回收次数超过10次,就会进行一次0代、1代和2代回收。而这里的几个值是通过查询get_threshold()返回(700,10,10)得到的。此外,gc模块还提供了手动回收的函数,即gc.collect()。
1 | a = [] |
而垃圾回收还有一个重要功能是,解决循环引用的问题,通常发生在某个变量a引用了自己或者变量a与b互相引用。考虑引用自己的情况,可以从下面的例子中看到,a所指向的内存对象有3个引用,但是实际上只有两个变量,假如把这两个变量都del掉,对象引用个数还是1,没有变成0,这种情况下,如果只有引用计数的机制,那么这块没有用的内存会一直无法释放掉。
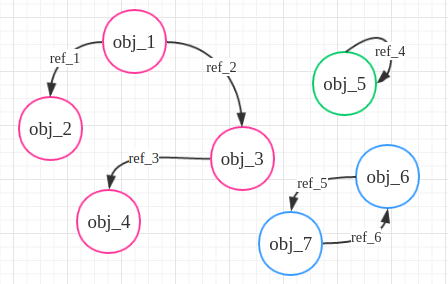
python的gc模块利用了“标记-清除”法,即认为有效的对象之间能通过有向图连接起来,其中图的节点是对象,而边是引用,上图中obj代表对象,ref代表引用,从一些不能被释放的对象节点出发(称为root object,一些全局引用或者函数栈中的引用[5],例如上图的obj_1,箭头表示obj_1引用了obj_2)遍历各代引用数不为0的对象。在python源码中,每个变量不仅有一个引用计数,还有一个有效引用计数gc_ref,后者一开始等于前者,但是启动标记清除法开始遍历对象时,从root object出发(初始图中的gc_ref为(1,1,1,1,1,1,1)),当对象i引用了对象j时,将对象j的有效引用个数减去1,这样上图中各个对象有效引用个数变为了(1, 0, 0, 0, 0, 0, 0),接着将所有对象分配到两个表中,一个是reachable对象表,一个是unreachable对象表,root object和在图中能够直接或者间接与它们相连的对象就放入reachable,而不能通过root object访问到且有效引用个数变为0的对象作为放入unreachable,从而通过这种方式来消去循环引用的影响。
在人工调用gc.collect()的时候会有一个返回值,这个返回值就是这一次扫描unreachable的对象个数。在上面谈到的每一代的回收过程中,都会启用“标记-清除”法。
1 | a = [] |
各种操作对变量地址的改变
当处理赋值、加减乘除时,这些操作实际上导致变量指向的对象发生了改变,已经不是原来的那个对象了,并不是通过这个变量来改变它指向的对象的值。
1 | a = 10 |
增加减少list、dict对象内容是在对对象本身进行操作,此时变量的指向并没有改变,它作为对象的一个别名/引用,通过操纵变量来改变对应的对象内容。但是一旦将变量赋值到别的地方去,那么变量地址就改变了。
1 | a = [] |
当把一个list变量赋值给另外一个变量时,这两个变量是等价的,它们都是原来对象的一个引用。
1 | a = [] |
但是实际使用中,可能需要的是将里面的内容给复制出来到一个新的地址空间,这里可以使用python的copy模块,copy模块分为两种拷贝,一种是浅拷贝,一种是深拷贝。假设处理一个list对象,浅拷贝调用函数copy.copy(),产生了一块新的内存来存放list中的每个元素引用,也就是说每个元素的跟原来list中元素地址是一样的。所以从下面例子中可看出当原list中要是包含list对象,分别在a和b对list元素做操作时,两边都受到了影响。此外,通过b=list(a)来对变量b赋值时,也跟浅拷贝的效果一样。
1 | a = [1, 1000, ['a', 'b']] |
而深拷贝则调用copy.deepcopy(),它将原list中每个元素都复制了值到新的内存中去了,因此跟原来的元素地址不相同,那么再对a和b的元素做操作,就是互相不影响了。
1 | a = [1, 1000, ['a', 'b']] |
当把一个变量传入一个函数时,它对应的对象引用个数增加2。