CMS垃圾回收分析
继上次对于JVM原理以及各种垃圾算法进行说明,本文主要对于CMS的回收过程以及日志进行分析。
JVM配置
-Xms3g -Xmx3g
-XX:+UseConcMarkSweepGC
-XX:CMSMaxAbortablePrecleanTime=5000
-XX:+CMSClassUnloadingEnabled
-XX:CMSInitiatingOccupancyFraction=80 (old区百分之80触发cms gc,跟UseCMSInitiatingOccupancyOnly一起配合使用)
-XX:+UseCMSInitiatingOccupancyOnly
GC日志
2017-05-15T02:23:07.219-0200[1] : 64.322[2] :[GC[3] (Allocation Failure[4] ) 64.322: [ParNew[5] : 274061K->1740K[6] (306688K)[7] , 0.0186772 secs[8] ] 1027804K->755578K[9] (3111680K)[10] , 0.0190341 secs[11] ][Times: user=0.08 sys=0.01, real=0.01 secs][12]
- 2017-05-15T02:23:07.219-0200 – GC发生的时间;
- 64.322 – GC开始,相对JVM启动的相对时间,单位是秒;
- GC – 区别MinorGC和FullGC的标识,这次代表的是MinorGC;
- Allocation Failure – MinorGC的原因,在这个case里边,由于年轻代不满足申请的空间,因此触发了MinorGC;
- ParNew – 收集器的名称,它预示了年轻代使用一个并行的 mark-copy stop-the-world 垃圾收集器;
- 274061K->1740K – 收集前后年轻代的使用情况;
- (306688K) – 整个年轻代的容量;
- 0.0186772 secs 耗时
- 1027804K->755578K – 收集前后整个堆的使用情况;
- 3111680K 整个堆的容量;
- 0.0190341 secs – ParNew收集器标记和复制年轻代活着的对象所花费的时间(包括和老年代通信的开销、对象晋升到老年代时间、垃圾收集周期结束一些最后的清理对象等的花销);
- [Times: user=0.78 sys=0.01, real=0.11 secs] – GC事件在不同维度的耗时,
- user – Total CPU time that was consumed by Garbage Collector threads during this collection
- sys – Time spent in OS calls or waiting for system event
- real – Clock time for which your application was stopped. With Parallel GC this number should be close to (user time + system time) divided by the number of threads used by the Garbage Collector. In this particular case 8 threads were used. Note that due to some activities not being parallelizable, it always exceeds the ratio by a certain amount.
开始的时候:整个堆的大小是 1027804K,年轻代大小是274061K,这说明老年代大小是 1027804K-274061K=753743k,
收集完成之后:整个堆的大小是 755578K,年轻代大小是1740K,这说明老年代大小是 755578K-1740K=753838k,
老年代的大小增加了:753838k-753743k=95k,也就是说 年轻代到年老代promot了95k的数据;
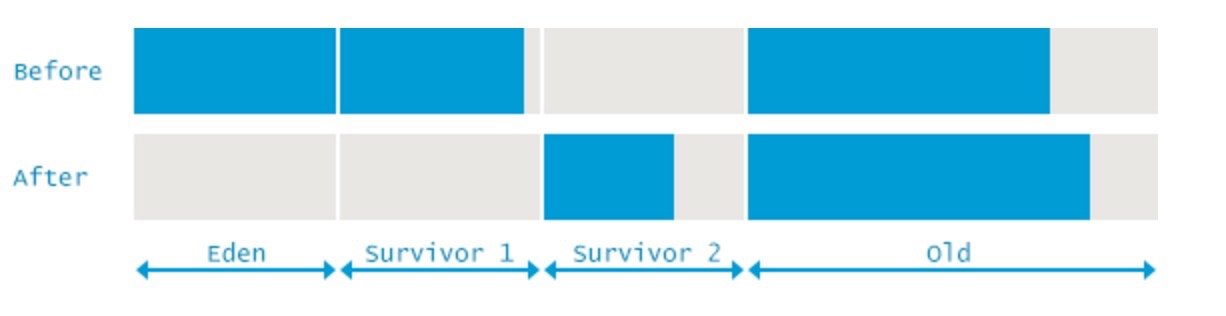
CMS GC
4391.322: [GC [1 CMS-initial-mark: 655374K(1310720K)] 662197K(1546688K), 0.0303050 secs] [Times: user=0.02 sys=0.02, real=0.03 secs]
4391.352: [CMS-concurrent-mark-start]4391.779: [CMS-concurrent-mark: 0.427/0.427 secs] [Times: user=1.24 sys=0.31, real=0.42 secs]
4391.779: [CMS-concurrent-preclean-start]
4391.821: [CMS-concurrent-preclean: 0.040/0.042 secs] [Times: user=0.13 sys=0.03, real=0.05 secs]
4391.821: [CMS-concurrent-abortable-preclean-start]
4392.511: [CMS-concurrent-abortable-preclean: 0.349/0.690 secs] [Times: user=2.02 sys=0.51, real=0.69 secs]
4392.516: [GC[YG occupancy: 111001 K (235968 K)]
4392.516: [Rescan (parallel) , 0.0309960 secs]
4392.547: [weak refs processing, 0.0417710 secs] [1 CMS-remark: 655734K(1310720K)] 766736K(1546688K), 0.0932010 secs] [Times: user=0.17 sys=0.00, real=0.09 secs]
4392.609: [CMS-concurrent-sweep-start]
4394.310: [CMS-concurrent-sweep: 1.595/1.701 secs] [Times: user=4.78 sys=1.05, real=1.70 secs]
4394.310: [CMS-concurrent-reset-start]
4394.364: [CMS-concurrent-reset: 0.054/0.054 secs] [Times: user=0.14 sys=0.06, real=0.06 secs]
过程分析
- 触发动作
- 初始标记(CMS-initial-mark)
- 并发标记(Concurrent marking)
- 并发预清理(Concurrent precleaning)
- 重新标记(STW remark)
- 并发清理(Concurrent sweeping)
- 并发重置(Concurrent reset)
触发动作
根据CMSInitiatingOccupancyFraction,UseCMSInitiatingOccupancyOnly来决定什么时间开始垃圾收集。
如果没有设置-XX:+UseCMSInitiatingOccupancyOnly,那么系统会根据统计数据自行决定什么时候触发cms gc。
CMS-initial-mark
此阶段是初始标记阶段,是stop the world阶段,垃圾回收的”根对象”开始,只扫描到能够和”根对象”直接关联的对象,并作标记;
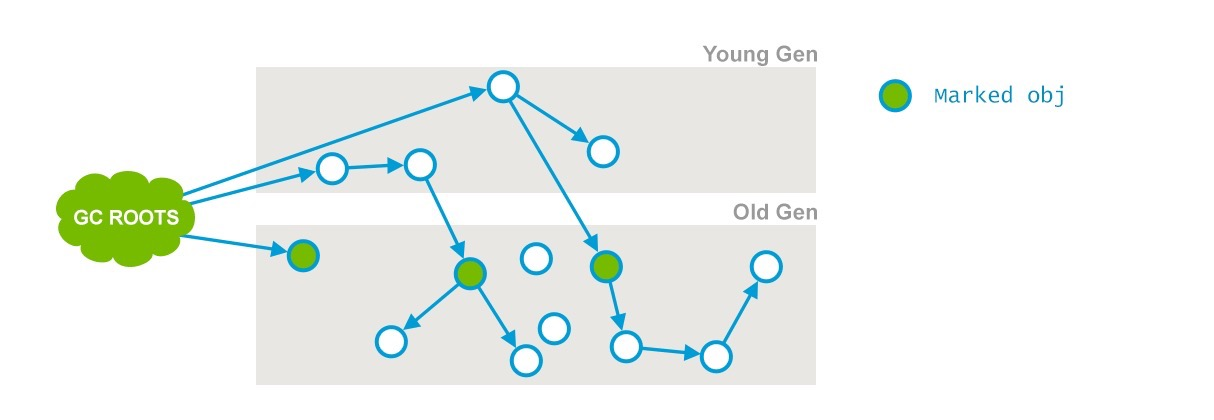
1 | CMS-initial-mark:961330K(1572864K),指标记时,old代的已用空间和总空间 |
CMS-concurrent-mark
阶段是和应用线程并发执行的,主要作用是在初始标记的基础上继续向下追溯标记,标记可达的对象.
这个阶段会遍历整个老年代并且标记所有存活的对象,从“初始化标记”阶段找到的GC Roots开始。并不是老年代的所有存活对象都会被标记,因为标记的同时应用程序会改变一些对象的引用等。
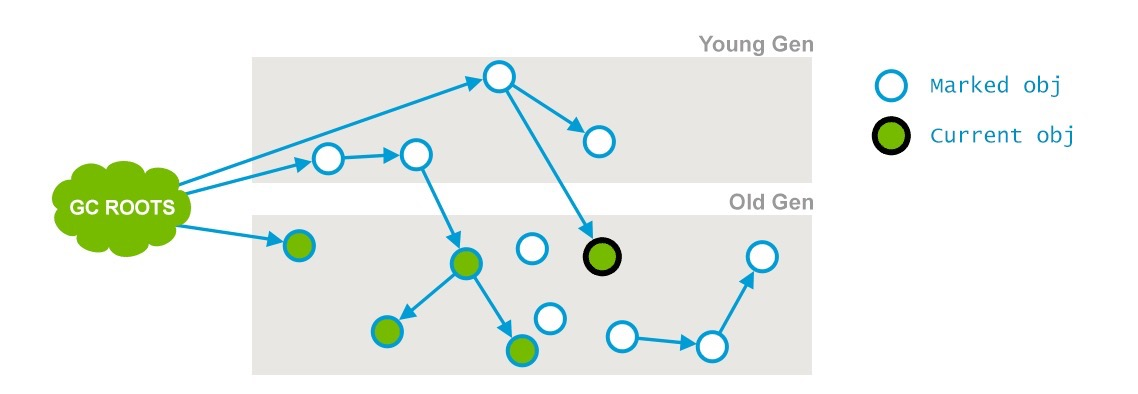
1 | CMS-concurrent-mark-start |
Concurrent-precleaning
前一个阶段在并行运行的时候,一些对象的引用已经发生了变化,当这些引用发生变化的时候,JVM会标记堆的这个区域为Dirty Card(包含被标记但是改变了的对象,被认为”dirty”),这就是 Card Marking。
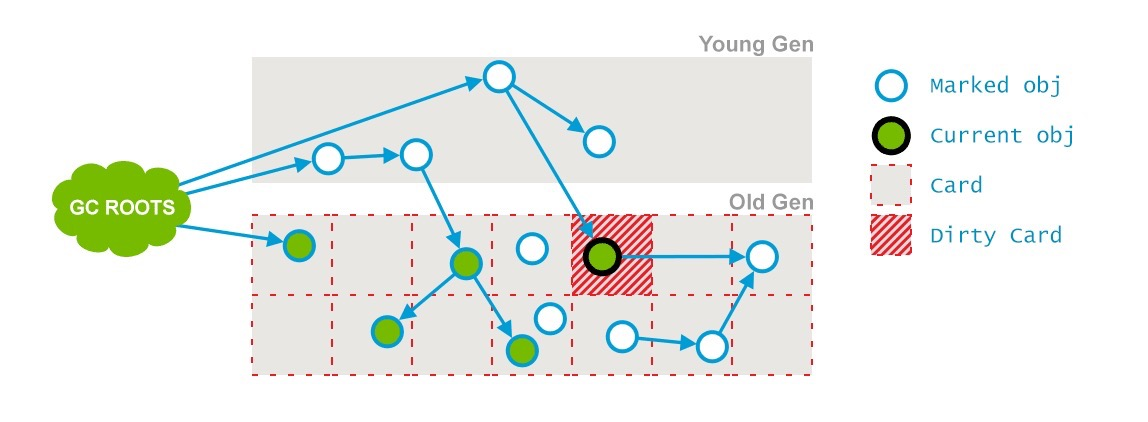
那些能够从dirty card对象到达的对象也会被标记,这个标记做完之后,dirty card标记就会被清除了。
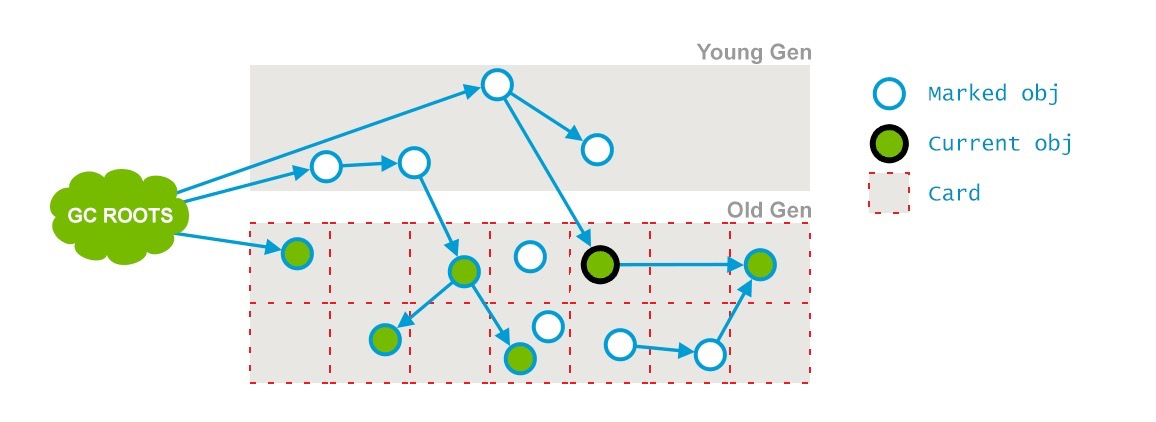
1 | CMS-concurrent-mark-start |
Abortable-preclean
这个阶段尝试着去承担STW的Final Remark阶段足够多的工作。这个阶段持续的时间依赖好多的因素,由于这个阶段是重复的做相同的事情直到发生aboart的条件(比如:重复的次数、多少量的工作、持续的时间等等)之一才会停止。
此阶段涉及几个参数:
-XX:CMSMaxAbortablePrecleanTime:当abortable-preclean阶段执行达到这个时间时才会结束
-XX:CMSScheduleRemarkEdenSizeThreshold(默认2m):控制abortable-preclean阶段什么时候开始执行, 即当eden使用达到此值时,才会开始abortable-preclean阶段
-XX:CMSScheduleRemarkEdenPenetratio(默认50%):控制abortable-preclean阶段什么时候结束执行
1 | CMS-concurrent-abortable-preclean-start |
Final-remark
第二个stop the world阶段了,此阶段暂停应用线程,对对象进行重新扫描并标记。由于之前的预处理是并发的,它可能跟不上应用程序改变的速度,这个时候,STW是非常需要的来完成这个严酷考验的阶段。
YG occupancy:964861K(2403008K),指执行时young代的情况
CMS remark:961330K(1572864K),指执行时old代的情况
Sweeping
这个阶段的目的就是移除那些不用的对象,回收他们占用的空间并且为将来使用。
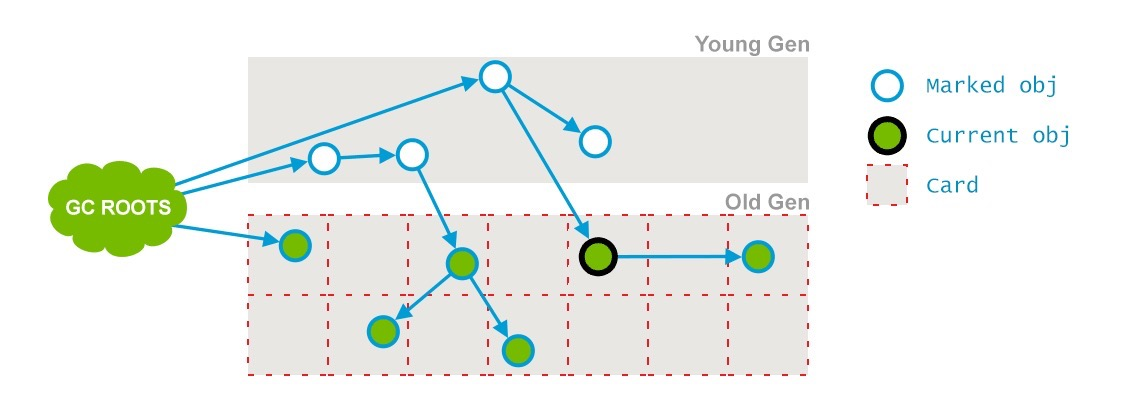
Reset
这个阶段并发执行,重新设置CMS算法内部的数据结构,准备下一个CMS生命周期的使用。
Full-GC
有2种情况会触发full gc,在full gc时,整个应用会暂停。
- concurrent-mode-failure:当cms gc正进行时,此时有新的对象要进行old代,但是old代空间不足造成的;
- promotion-failed:当进行young gc时,有部分young代对象仍然可用,但是S1或S2放不下,因此需要放到old代,但此时old代空间无法容纳这些对象。
影响cms gc时长及触发的参数是以下2个:
-XX:CMSMaxAbortablePrecleanTime=5000
-XX:CMSInitiatingOccupancyFraction=80
解决也是针对这两个参数来的,根本的原因是每次请求消耗的内存量过大解决方式:
- 针对cms gc的触发阶段,调整
- XX:CMSInitiatingOccupancyFraction=50,提早触发cms gc,就可以缓解当old代达到80%,cms gc处理不完,从而造成concurrent mode failure引发full gc
- 修改-XX:CMSMaxAbortablePrecleanTime=500,缩小CMS-concurrent-abortable-preclean阶段的时间
- 考虑到cms gc时不会进行compact,因此加入
- XX:+UseCMSCompactAtFullCollection (cms gc后会进行内存的compact)和-XX:CMSFullGCsBeforeCompaction=4(在full gc4次后会进行compact)参数
CMS缺点
- CMS回收器采用的基础算法是Mark-Sweep。所以CMS不会整理、压缩堆空间。这样就会有一个问题:经过CMS收集的堆会产生空间碎片。 CMS不对堆空间整理压缩节约了垃圾回收的停顿时间,但也带来的堆空间的浪费。为了解决堆空间浪费问题,CMS回收器不再采用简单的指针指向一块可用堆空 间来为下次对象分配使用。而是把一些未分配的空间汇总成一个列表,当JVM分配对象空间的时候,会搜索这个列表找到足够大的空间来hold住这个对象。
- 需要更多的CPU资源。从上面的图可以看到,为了让应用程序不停顿,CMS线程和应用程序线程并发执行,这样就需要有更多的CPU,单纯靠线程切 换是不靠谱的。并且,重新标记阶段,为空保证STW快速完成,也要用到更多的甚至所有的CPU资源。当然,多核多CPU也是未来的趋势!
- CMS的另一个缺点是它需要更大的堆空间。因为CMS标记阶段应用程序的线程还是在执行的,那么就会有堆空间继续分配的情况,为了保证在CMS回 收完堆之前还有空间分配给正在运行的应用程序,必须预留一部分空间。也就是说,CMS不会在老年代满的时候才开始收集。相反,它会尝试更早的开始收集,以避免上面提到的情况:在回收完成之前,堆没有足够空间分配!默认当老年代使用68%的时候,CMS就开始行动了。 通过–XX:CMSInitiatingOccupancyFraction = n 来设置这个阀值。
总结
总的来说,CMS回收器减少了回收的停顿时间,但是降低了堆空间的利用率。
如果你的应用程序对停顿比较敏感,并且在应用程序运行的时候可以提供更大的内存和更多的CPU(也就是硬件牛逼),那么使用CMS来收集会给你带来好处。还有,如果在JVM中,有相对较多存活时间较长的对象(老年代比较大)会更适合使用CMS。