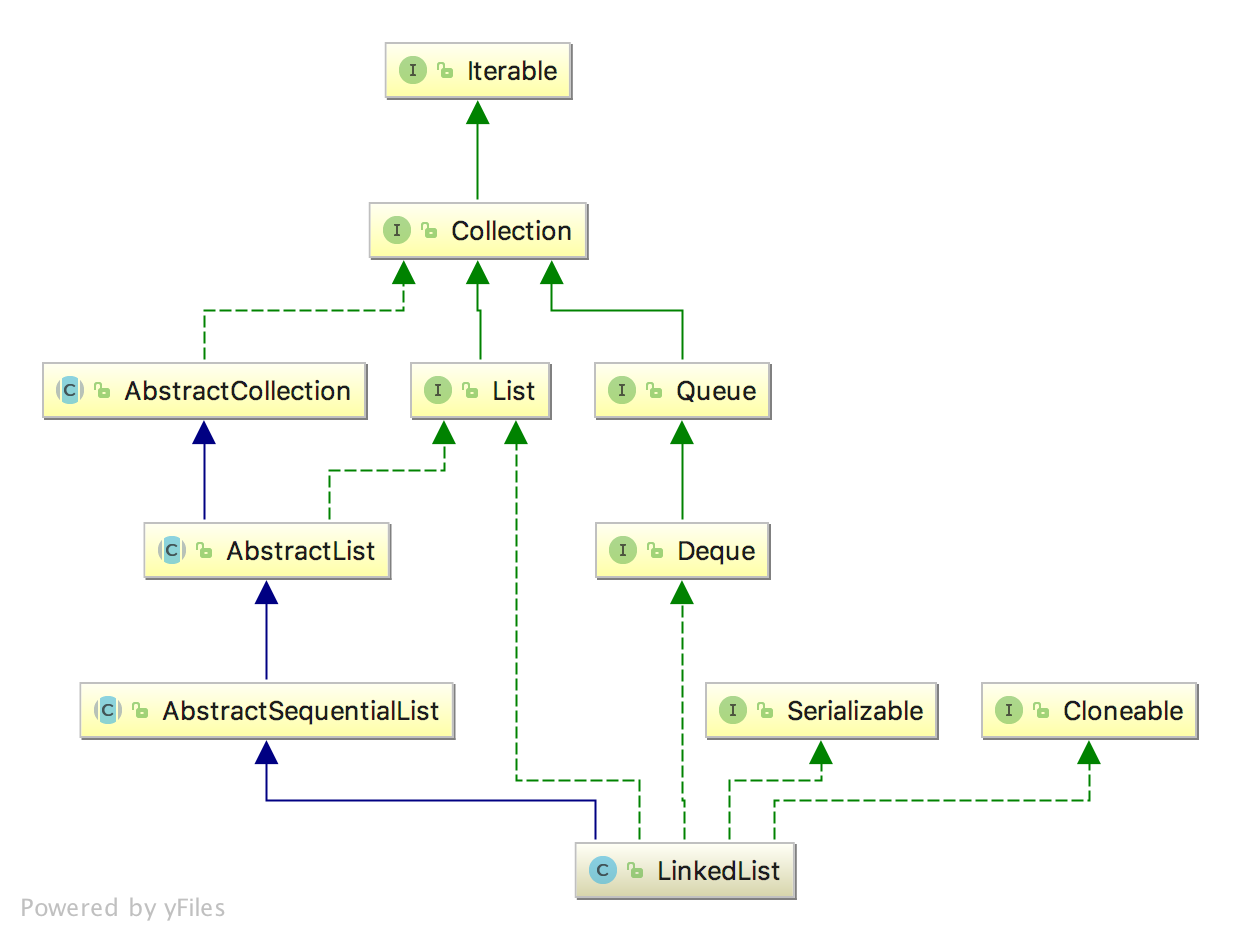
if (index == size) linkLast(element); else linkBefore(element, node(index)); } Node<E> node(int index){ // 若在前半段,从前往后遍历;反之,从后往前遍历。返回index处的非空节点 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } } privatevoidlinkFirst(E e){ final Node<E> f = first; final Node<E> newNode = new Node<>(null, e, f); first = newNode; if (f == null) last = newNode; else f.prev = newNode; size++; modCount++; } voidlinkLast(E e){ final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; } voidlinkBefore(E e, Node<E> succ){ final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++; }
Object[] a = c.toArray(); int numNew = a.length; if (numNew == 0) returnfalse;
Node<E> pred, succ; if (index == size) { succ = null; pred = last; } else { succ = node(index); pred = succ.prev; }
for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o; Node<E> newNode = new Node<>(pred, e, null); if (pred == null) first = newNode; else pred.next = newNode; pred = newNode; }
if (succ == null) { last = pred; } else { pred.next = succ; succ.prev = pred; }
public E remove(int index){ checkElementIndex(index); return unlink(node(index)); }
public E removeFirst(){ final Node<E> f = first; if (f == null) thrownew NoSuchElementException(); return unlinkFirst(f); }
private E unlinkFirst(Node<E> f){ // assert f == first && f != null; final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element; }
E unlink(Node<E> x){ // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev;
if (prev == null) { first = next; } else { prev.next = next; x.prev = null; }
if (next == null) { last = prev; } else { next.prev = prev; x.next = null; }
publicintindexOf(Object o){ int index = 0; if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1; }
/** * Adds the specified element as the tail (last element) of this list. * * @param e the element to add * @return {@code true} (as specified by {@link Queue#offer}) * @since 1.5 */ publicbooleanoffer(E e){ return add(e); }
/** * Retrieves and removes the head (first element) of this list. * * @return the head of this list, or {@code null} if this list is empty * @since 1.5 */ public E poll(){ final Node<E> f = first; return (f == null) ? null : unlinkFirst(f); }
/** * Unlinks non-null first node f. */ private E unlinkFirst(Node<E> f){ // assert f == first && f != null; final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element; }
/** * Retrieves, but does not remove, the head (first element) of this list. * * @return the head of this list, or {@code null} if this list is empty * @since 1.5 */ public E peek(){ final Node<E> f = first; return (f == null) ? null : f.item; }
/** * Returns the first element in this list. * * @return the first element in this list * @throws NoSuchElementException if this list is empty */ public E getFirst(){ final Node<E> f = first; if (f == null) thrownew NoSuchElementException(); return f.item; }
/** * Pushes an element onto the stack represented by this list. In other * words, inserts the element at the front of this list. * * <p>This method is equivalent to {@link #addFirst}. * * @param e the element to push * @since 1.6 */ publicvoidpush(E e){ addFirst(e); }
/** * Inserts the specified element at the beginning of this list. * * @param e the element to add */ publicvoidaddFirst(E e){ linkFirst(e); }
/** * Links e as first element. */ privatevoidlinkFirst(E e){ final Node<E> f = first; final Node<E> newNode = new Node<>(null, e, f); first = newNode; if (f == null) last = newNode; else f.prev = newNode; size++; modCount++; }