Java源码解析 —— Map总结
各类Map详解
Map接口定义了一个保存key-value的对象,该对象中key值是不存在重复的,每个key值至多对应一个value。
在前面几篇的文章中分别介绍了Map的实现类,如HashMap、Hashtable、TreeMap,详细可以查看:
类图结构
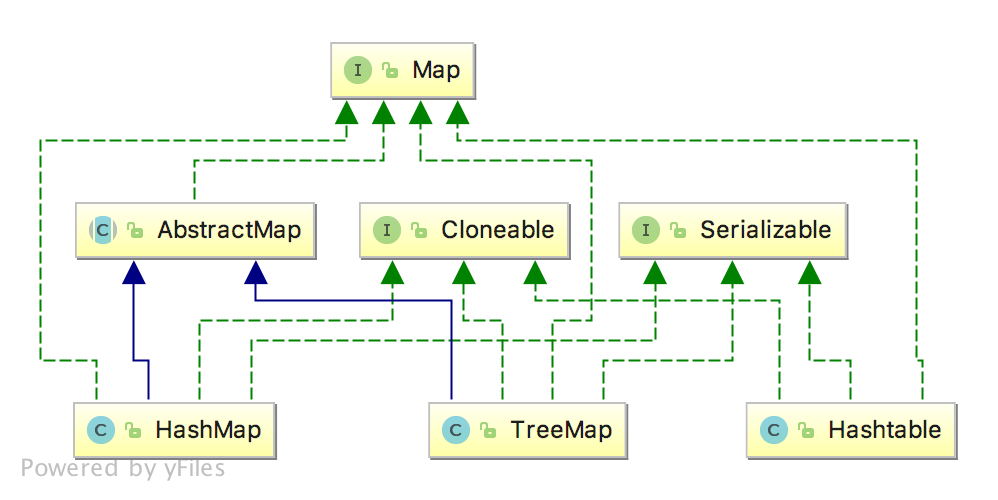
如上图所示是实现Map接口的类图结构,主要包含了如下的类与接口:
- Map接口:定义将键值映射到值的对象,Map规定不能包含重复的键值,每个键最多可以映射一个值,这个接口是用来替换Dictionary类。
- AbstractMap类:提供了一个Map骨架的实现,尽量减少了实现Map接口所需要的工作量
- HashMap类:HashMap是实现了Map接口的key-value集合,实现了所有map的操作,允许key和value为null,它相当于Hashtable,与之存在的区别是hashMap不是线程安全的,HashMap允许null值。
- TreeMap类:TreeMap是基于红黑树的实现,也是记录了key-value的映射关系,该映射根据key的自然排序进行排序或者根据构造方法中传入的比较器进行排序,也就是说TreeMap是有序的key-value集合
- Hashtable类:它是类似与HashMap的key-value的哈希表,不允许key-value为NULL值,另外一点值得注意的是Hashtable是线程安全的
- Serializable接口:实现了该接口标识了类可以被序列化和反序列化,具体的 查询序列化详解
- Cloneable接口:实现了该接口的类可以显示的调用Object.clone()方法,合法的对该类实例进行字段复制,如果没有实现Cloneable接口的实例上调用Obejct.clone()方法,会抛出CloneNotSupportException异常。正常情况下,实现了Cloneable接口的类会以公共方法重写Object.clone()
比较
虽然HashMap、Hashtable、TreeMap这三个都是Map接口的实现,其内部实现及性能等还是存在区别,下面将从区别及性能两个方面去分析。
区别
基本
- HashMap:初始化容量为16,扩容每次为2 * oldCap, key-value可以为NULL值
- Hashtable:初始化容量为11,扩容每次为2 * oldCap + 1, key-value不可以为NULL值
- TreeMap:初始化容量为0,内部是红黑树结构,不存在hash冲突的情况,不存在扩容的操作, key-value不可以为NULL值
实现
- HashMap:实现了Map接口,继承了AbstractMap类
- Hashtable:实现了Map接口,继承了AbstractMap类
- TreeMap:由于TreeMap是有序的,所以其除了实现了Map接口,还实现了SortedMap、NavigableMap接口
内部原理
- HashMap:HashMap是散列表实现,内部是数组+链表或者红黑树的结构
- Hashtable:Hashtable也是散列表实现,内部是数组+链表的结构
- TreeMap:TreeMap内部是红黑树的结构
线程安全性
- HashMap:不是线程安全的,其实通过
Map m = Collections.synchronizeMap(hashMap)的方式也可以使得HashMap变成线程安全的,但是这样做对程序的性能可能是噩梦,在后面会介绍ConcurrentHashMap,建议在多线程的情况下可以使用ConcurrentHashMap替换HashMap - Hashtable:是线程安全的,内部方法使用关键字synchronized修饰
- TreeMap:不是线程安全的
性能
按照如下代码对HashMap、Hashtable、TreeMap的性能进行测试:
1 | public class HashMapProgress { |
分别测试了100000, 1000000, 10000000个数据的情况,测试结果如下所示:
| 数据量 | HashMap | HashTable | TreeMap |
|---|---|---|---|
| 100000 | 插入用时:18s 查询用时:9s | 插入用时:14s 查询用时:5s | 插入用时:33s 查询用时:17s |
| 1000000 | 插入用时:98s 查询用时:20s | 插入用时:625s 查询用时:31s | 插入用时:242s 查询用时: 145s |
| 1000000 | 插入用时:9773s 查询用时:811s | 插入用时:15055s 查询用时:3369s | 插入用时:22354s 查询用时: 3889s |
通过上表可以看出随着数据量的增加,时间变化差异还是很大的,而在单线程的情况下还是尽量使用HashMap,相对于Hashtable、TreeMap性能更好,而针对特定的情况需视情况而论。