Java源码解析 —— HashSet
前言
今天来介绍下HashSet。前面,我们已经系统的对List和Map进行了学习。接下来,我们开始可以学习Set。相信经过Map的了解之后,学习Set会容易很多。毕竟,Set的实现类都是基于Map来实现的(HashSet是通过HashMap实现的)。
构造图如下:
蓝色线条:继承
绿色线条:接口实现
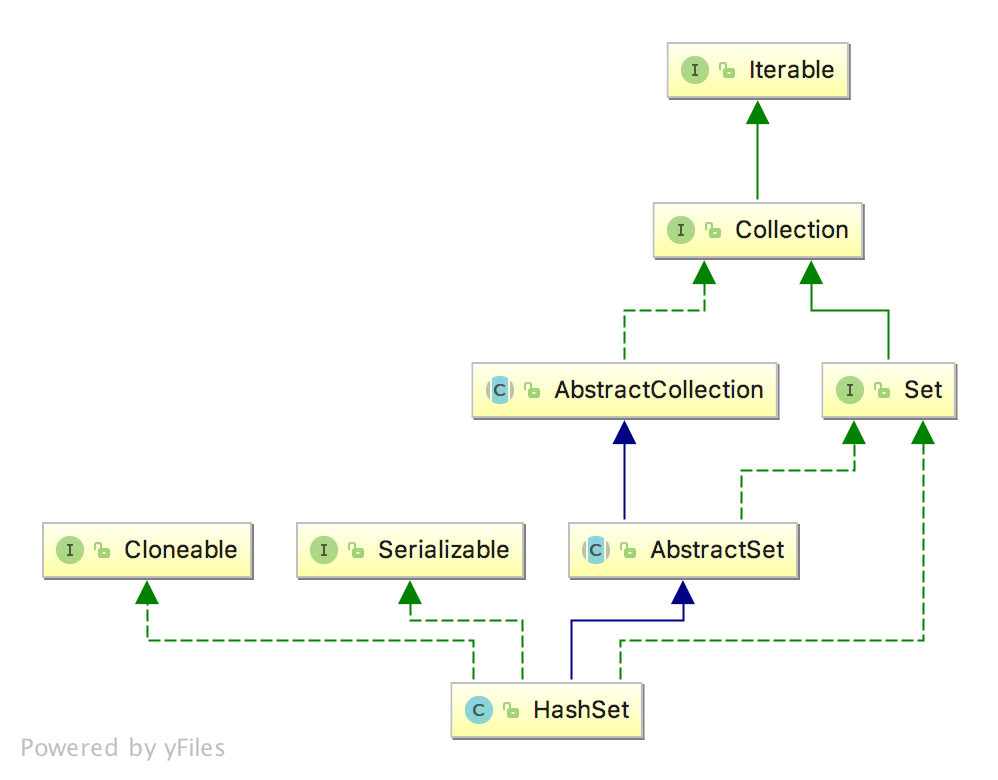
HashSet简介
对于HashSet而言,它是基于HashMap来实现的,底层采用HashMap来保存元素。
定义
1 | public class HashSet<E> |
HashSet是一个没有重复元素的集合。
它是由HashMap实现的,不保证元素的顺序,而且HashSet允许使用null元素。
HashSet是非同步的。如果多个线程同时访问一个hashSet,而其中至少一个线程修改了该set,那么它必须保持外部同步。这通常是通过对自然封装该set的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet方法来“包装”set。最好在创建时完成这一操作,以防止对该set进行意外的不同步访问:
1 | Set s = Collections.synchronizedSet(new HashSet(...)); |
HashSet通过iterator()返回的迭代器是fail-fast的。
HashSet属性
1 | // 底层使用HashMap来保存HashSet的元素 |
看到这里就明白了,和我们前面说的一样,HashSet是用HashMap来保存数据,而主要使用到的就是HashMap的key。
看到private static final Object PRESENT = new Object();不知道你有没有一点疑问呢。这里使用一个静态的常量Object类来充当HashMap的value,既然这里map的value是没有意义的,为什么不直接使用null值来充当value呢?比如写成这样子private final Object PRESENT = null;我们都知道的是,Java首先将变量PRESENT分配在栈空间,而将new出来的Object分配到堆空间,这里的new Object()是占用堆内存的(一个空的Object对象占用8byte),而null值我们知道,是不会在堆空间分配内存的。那么想一想这里为什么不使用null值。想到什么吗,看一个异常类java.lang.NullPointerException,Java号称没有指针,但是处处碰到NullPointerException。所以为了从根源上避免NullPointerException的出现,采用浪费8个byte,在下面的代码中就不会出现if (xxx == null) { … } else {….}。
HashSet构造函数
1 | /** |
源码解析
增加和删除
1 | /** |
是否包含
1 | /** |
由于HashMap基于hash表实现,hash表实现的容器最重要的一点就是可以快速存取,那么HashSet对于contains方法,利用HashMap的containsKey方法,效率是非常之快的。
容量检查
1 | /** |
HashSet遍历方式
通过Iterator遍历HashSet
- 根据iterator()获取HashSet的迭代器。
- 遍历迭代器获取各个元素。
1 | for(Iterator iterator = set.iterator(); |
通过for-each遍历HashSet
- 根据toArray()获取HashSet的元素集合对应的数组。
- 遍历数组,获取各个元素。
1 | String[] arr = (String[])set.toArray(new String[0]); |
总结
HashSet和HashMap的区别
| HashMap | HashSet |
|---|---|
| HashMap实现了Map接口 | HashSet实现了Set接口 |
| HashMap存储键值对KV | HashSet仅仅存储对象 |
| 使用put()方法将元素放进map中 | 使用add()方法将元素放到set中 |
| HashMap使用key对象来计算hashcode值 | HashSet中使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以用equals()方法来判断对象的相等性,如果两个对象不同返回false |
| HashMap比较快,因为用唯一的key来获取对象 | 较HashMap来说比较慢 |