Java多线程 —— 线程池原理及源码分析
使用线程池的好处
线程池也是池化技术的一个具体实现,这样说来,合理利用包括线程池等池化技术(如连接池等)能够带来三个好处:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
线程池的使用
在了解原理之前,先了解一下如何使用它,玩熟了再往深处挖。
线程池的创建
我们首先来看一下线程池的默认构造函数,以及可传入的参数:
1 | public ThreadPoolExecutor(int corePoolSize, |
- corePoolSize:线程池中常驻核心线程数;
- maximumPoolSize:能够容纳同时执行的最大线程数,必须大于等于1;
- keepAliveTime:多余的空闲线程存活时间(当前线程数超过corePoolSize时,空闲时间超过keepAliveTime时,多余线程会被销毁直到只剩下corePoolSize个线程为止);
- unit:keepAliveTime的单位;
- workQueue:任务队列,被提交但尚未被执行的任务;
- threadFactory:生成线程池中工作线程的线程工厂,用于创建线程,一般用默认的即可;
- handler:拒绝策略,当队列满了,并且工作线程大于等于最大线程数,执行拒绝策略。
这里要对两个重点概念进行说明:
workQueue
workQueue是用于保存等待执行的任务的阻塞队列。可以选择以下几个阻塞队列:
| 队列 | 说明 |
|---|---|
| ☆ArrayBlockingQueue | 数组结构组成的有界阻塞队列 |
| ☆LinkedBlockingQueue | 链表结构组成的有界(大小默认值为Integer.MAX_VALUE)阻塞队列(相当于无界) |
| PriorityBlockingQueue | 支持优先级排序的无界阻塞队列 |
| DelayQueue | 使用优先级队列实现的延迟无界阻塞队列 |
| ☆SynchronousQueue | 不存储元素的阻塞队列,也即单个元素的队列 |
| LinkedTransferQueue | 链表结构组成的无界阻塞队列 |
| LinkedBlockingDeque | 链表结构组成的双向阻塞队列 |
handler(RejectHandler)
RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。
以下是JDK1.8提供的四种策略:
| 策略 | 说明 |
|---|---|
| AbortPolicy | (默认实现,不敢用,动不动就崩)直接抛出异常。 |
| CallerRunsPolicy | 即不会抛弃任务,又不会抛出异常,而是将任务回退到调用者(比如退给main线程执行),从而降低新任务的流量。 |
| DiscardOldestPolicy | 丢弃队列里呆的最久的一个任务,然后把当前任务加入到队列中尝试再次提交。 |
| DiscardPolicy | 不处理,丢弃掉,也不抛出异常。如果允许任务丢失,这是最好的一种方案。 |
| 实现RejectedExecutionHandler接口 | 当然也可以根据应用场景需要来实现RejectedExecutionHandler接口自定义策略。如记录日志或持久化不能处理的任务。 |
提交任务
线程池允许我们使用execute()和submit()两种方法提交任务:
- execute提交任务,但是execute方法没有返回值,所以无法判断提交的任务是否被线程池执行成功;
- submit方法来提交任务,它会将task封装为一个futureTask(后面我们还会提到),并返回一个future,那么我们可以通过这个future来判断任务是否执行成功,通过future的get方法来获取返回值。
- get()方法会阻塞住直到任务完成,而使用get(long timeout, TimeUnit unit)方法则会阻塞一段时间后立即返回,这时有可能任务没有执行完。
线程池的关闭
我们可以通过调用线程池的shutdown()或shutdownNow()方法来关闭线程池,但是它们的实现原理不同:
- shutdown()的原理是只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程;
- shutdownNow()的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。shutdownNow会首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表。
只要调用了这两个关闭方法的其中一个,isShutdown()方法就会返回true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminated()方法会返回true。至于我们应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用shutdown()来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow()。
线程池的工作原理
工作流程
线程池的主要工作流程如下图:
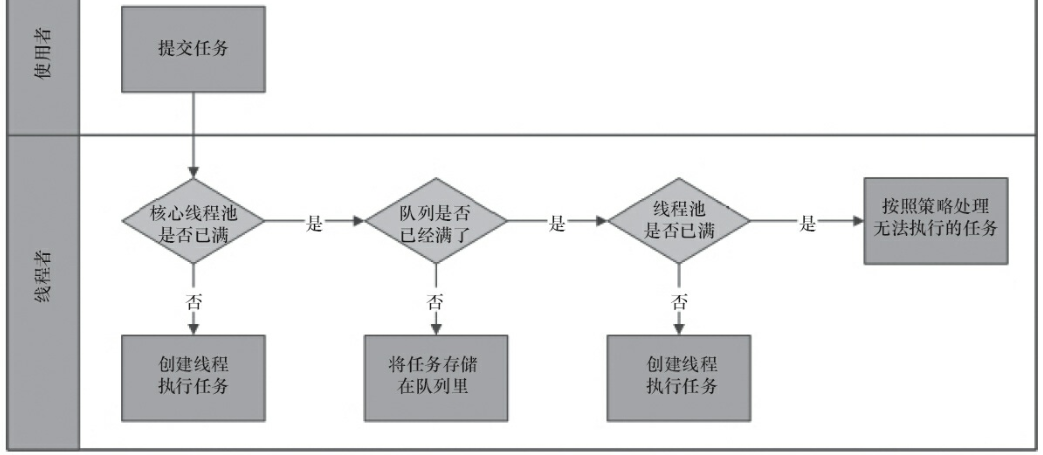
我们可以看出,当提交一个新任务到线程池时,线程池的处理流程如下:
- 首先线程池判断核心线程池是否已满?没满,创建一个工作线程来执行任务。满了,则进入下个流程。
- 其次线程池判断工作队列是否已满?没满,则将新提交的任务存储在工作队列里。满了,则进入下个流程。
- 最后线程池判断整个线程池是否已满?没满,则创建一个新的工作线程来执行任务,满了,则交给饱和策略来处理这个任务。
线程池提交任务源码分析
这里我们还是分为submit和execute两种方式来分析。
当线程池调用submit()方法提交任务时,线程池会首先将这个Runnable的task封装为一个futureTask,然后跟execute的方式一样直接调用execute()方法来执行,此后将这个futureTask返回,便于以后get()来获取运行结果或拿到异常:
1 | public Future<?> submit(Runnable task) { |
其后,这两种提交方式走的是同样的代码路径了。线程池调用executor()执行任务的方法如下(execute方式入口):
1 | public void execute(Runnable command) { |
接下来我们看一下execute()中多次调用的addWorker()方法,它的主要工作是在线程池中创建一个新的线程并执行:
参数:
- firstTask:指定新创建的线程执行的第一个任务,为null则不执行任务;
- core:如果是true则使用corePoolSize来绑定,否则使用maximumPoolSize绑定。
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
线程池的异常处理
关于线程池的异常处理,这其实源于一次踩坑,现象是我发现通过submit()方法提交task(除0异常)之后,异常不打印出来了:
1 | public static void main(String[] args) { |
控制台输出:
1 | /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/bin/java ... |
而通过execute()方法直接执行task,会抛出对应的异常:
1 | public static void main(String[] args) { |
控制台输出:
1 | test thread |
其实线程池对于异常的处理,跟提交线程的方式有关,分为submit的方式和execute的方式。
submit获取异常
上面我们分析过,submit()方法,是在AbstractExecutorService中实现的,它会将task封装成一个futureTask,然后execute()去执行。
接下来execute()方法是在ThreadPoolExecutor中实现的,整个execute()方法就是判断线程池状态,然后选择到底是new线程来执行还是加入等待队列,做事情的就是addWorker(),然后就会调用内部类Worker的run()方法。
在runWorker()中会调用futureTask的run()方法,如果出现了异常,会将这个Exception通过setException()的方式吞掉,它认为异常也是这个task执行的一部分。
1 | try { |
如果想拿到这个异常,需要调用futureTask的get()方法。
execute直接抛出异常
如果是execute()方法的话,task.run()直接调的就是Callable或者Runnable的run()方法了,所有的异常就直接抛了,因为没有futureTask的那层封装。
这里走的是Thread的run()方法。
UncaughtExceptionHandler是JVM调用的处理线程异常的:
1 | /** |
Executors类提供的几种线程池
理论聊了这么多,我们来看看juc中给我们提供了哪几种线程池的实现,以及它们各自都有什么特点。
线程池主要有5种(包含jdk 1.8):
1,Executors.newScheduledThreadPool():无限大小的线程池,每个线程存活时间是无限的,使用优先级队列实现的延迟无界阻塞队列,适用于周期性执行任务的场景。
1 | public static ExecutorService newScheduledThreadPool(int corePoolSize) { |
2,Executors.newFixedThreadPool(int):固定数量线程的池子,每个线程存活时间是无限的,使用无界阻塞队列,适用于执行长期的任务。
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
3,Executors.newSingleThreadPool():只有一个线程的池子,存活时间是无限的,使用无界阻塞队列,适用于一个任务一个任务执行的场景。
1 | public static ExecutorService newSingleThreadExecutor() { |
4,Executors.newCachedThreadPool():新任务到来就插入到同步队列中,并且同时寻找可用线程来执行,使用单个元素的队列,适用于短期异步的任务或者负载较轻的服务器。
1 | public static ExecutorService newCachedThreadPool() { |
5,Java8新出Executors.newWorkStealingPool(int):使用目前机器可用的处理器作为它的并行级别,采用ForkJoinPool来实现。
1 | public static ExecutorService newWorkStealingPool() { |
如何选择?
我们不禁眼花缭乱,juc给我们提供了如此多的的线程池的实现,那日常开发中如何选择哪种线程池来使用呢?
真相只有一个:哪个都不用!!!
【强制】《阿里巴巴Java开发手册》规定线程池不允许使用Executors去创建,而是通过
new ThreadPoolExecutor的方式。
也就是通过ThreadPoolExecutor直接构造方法的方式。这主要是因为Executors返回线程池对象有其弊端:
- FixedThreadPool和SingleThreadPool:允许请求队列长度为Integer.MAX_VALUE,可能会堆积大量请求,导致OOM;
- CachedThreadPool和ScheduledThreadPool:允许创建线程数量为Integer.MAX_VALUE,可能会创建大量线程,导致OOM。
那么我们在手动创建线程池时,如何合理配置呢?
合理配置线程池
从线程数量上来看:
以Runtime.getRuntime.availableProcessors()获得的CPU核数为基准:
- CPU密集型:配置Ncpu + 1个线程的线程池(线程数应当等于核心数,但是再怎么计算密集,总有一些IO吧,所以再加一个线程来把等待IO的CPU时间利用起来);
- IO密集型:线程并不是一直在执行任务,则配置尽可能多的线程,如2 * Ncpu;
- 或者Ncpu / (1 - 阻塞系数),阻塞系数在0.8 - 0.9之间,比如8核CPU, 8 / (1 - 0.9) = 80个线程;
- 看具体测出来的情况吧。
从任务的执行时间来看:
可以使用优先级队列,让执行时间短的任务先执行。
总结
本来之前写过一篇关于线程池的文章的,但过于浅显。自近日以来觉得做技术不光要会使用、熟练使用,更要深入到源码层面理解其工作原理。Talk is cheap,show me the code!自认为本篇文章由表入里,已经将线程池的大部分内容分析透彻了。