Golang对接Hive工具——gohive
背景
在对接Hive组件的开发实践,探索学习了golang操作hive的工具库,并实现了数据中心对接hive、操作hive数据集、导出下载hive表等功能。
但golang自带的sql库无法直接对hive进行操作,也没有官方库提供,网上又少有此类工具库的实现,经过调研,决定使用gohive。
golang操作Hive库
使用了gohive库操作tbds的Hive库表,gohive是golang操作Hive和Spark分布式SQL引擎的driver,提供两种验证机制:
- 支持不带鉴权连接Hive;
- 支持带有SSL的连接机制,包括kerberos、LDAP、CUSTOM和NOSASL
以上两种验证机制都支持http或者二进制的传输。
连接
创建连接(省略了错误处理):
1 | configuration := gohive.NewConnectConfiguration() |
Connect函数内部实现了类似ping的验证,所以Connect返回实例不为空,则连接成功。
使用query语句
在使用gohive拿到连接实例conn后,可通过conn的cursor来执行查询语句,并在查询结束后手动关闭cursor:
1 | ctx := context.Background() |
结果集包含在cursor实例中。
结果集解析
gohive通过cursor,即类似光标指针的方式,来操作查询和获取结果集。对于结果集的遍历赋值,gohive提供了2种方式:
使用RowMap
1 | for cursor.HasMore(ctx) { |
RowMap返回key为列名,value为表数据值的map[string]interface{},例如:
| user_id | user_name |
|---|---|
| 1 | zhangsan |
| 2 | lisi |
则随着光标后移(HasMore),RowMap:
- 第一次返回{“user_id”: 1, “user_name”:”zhangsan”}
- 第二次返回{“user_id”: 2, “user_name”: “lisi”}
指定参数赋值
上面的表结构,若已知结果集有参数数量和参数类型,可以直接使用FetchOne指定参数赋值:
1 | var userId int |
输出:
1 | id: 1, name: zhangsan |
这种方式若FetchOne传参个数不对,会报参数个数不匹配的错误。
遇到的问题
虽然gohive提供了方便连接和操作Hive库的方式,但是在使用gohive工具实践的过程中,同样也遇到了一些问题。
连接时间过长
在测试中发现,查询一张表的总行数时,请求响应时间竟然长达10秒:

经过排查,发现有2处操作比较耗时:
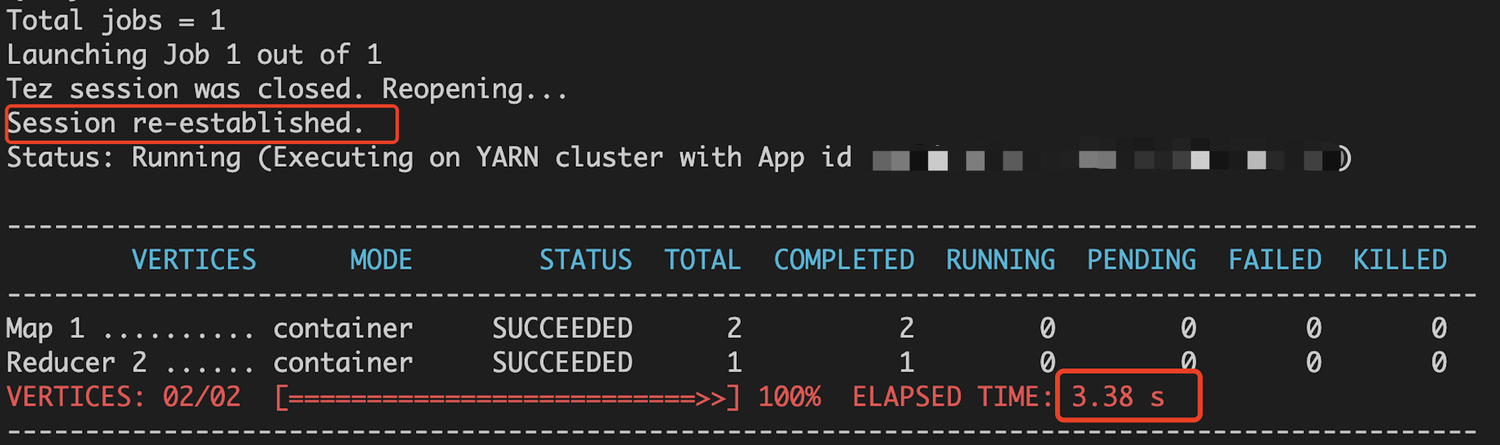
- 一是Hive引擎自身处理行数查询时(图中下面的红框框3.38秒),会起spark执行map-reduce任务,由于引擎本身与mysql存在差异,这部分时间无法优化(但是可以采用异步的方式,后面会介绍);
- 二是与Hive引擎重新建立连接的时间每次高达6秒,优化点可以将conn实例缓存起来,虽然长时间不使用会断开,但在timeout时间内做频繁查询则不需重新建立连接,一定程度上会起到查询优化的作用。
同步查询时间过长
cursor.Exec(ctx)使用的是同步查询,对于处理时间过长的查询,gohive提供了异步的查询接口,在查询过程中做其他的事,然后等待查询完成并解析结果集:
1 | cursor.Execute(ctx, query, true /*async*/) |
总结
本文介绍了使用golang操作Hive库表的工具gohive,以及分析了实践过程中遇到的问题和解决方案。